
Vector search leverages Machine Learning (ML) Vector search leverages Machine Learning (ML) to capture the meaning and context of unstructured data (such as text and images) and represent it in a digital form. It is commonly used in semantic search, where the Approximate Nearest Neighbor (ANN) algorithm is employed to find similar data. Compared to traditional keyword-based search, vector search delivers more relevant results and operates more efficiently. How many times have you tried to find something without knowing its exact name? You may know its purpose or how to describe it, but without keywords, you’re essentially searching in the dark. Vector search overcomes this limitation by enabling intent-based search. It provides fast and context-aware results, as vector embeddings capture synonyms and associations that represent the underlying meaning of the query. You can combine vector search with filtering and aggregation to enhance relevance through hybrid search, and integrate it with traditional scoring methods for a more powerful search experience.Definition
A vector search engine, also known as a vector database or semantic search engine, is designed to find the nearest neighbors of a given (vectorized) query.
Unlike traditional search methods that rely on keyword frequency, lexical similarity, or word occurrence, vector search engines use distance metrics in an embedding space to represent similarity. This makes finding relevant data equivalent to searching for the nearest neighbors of your query.
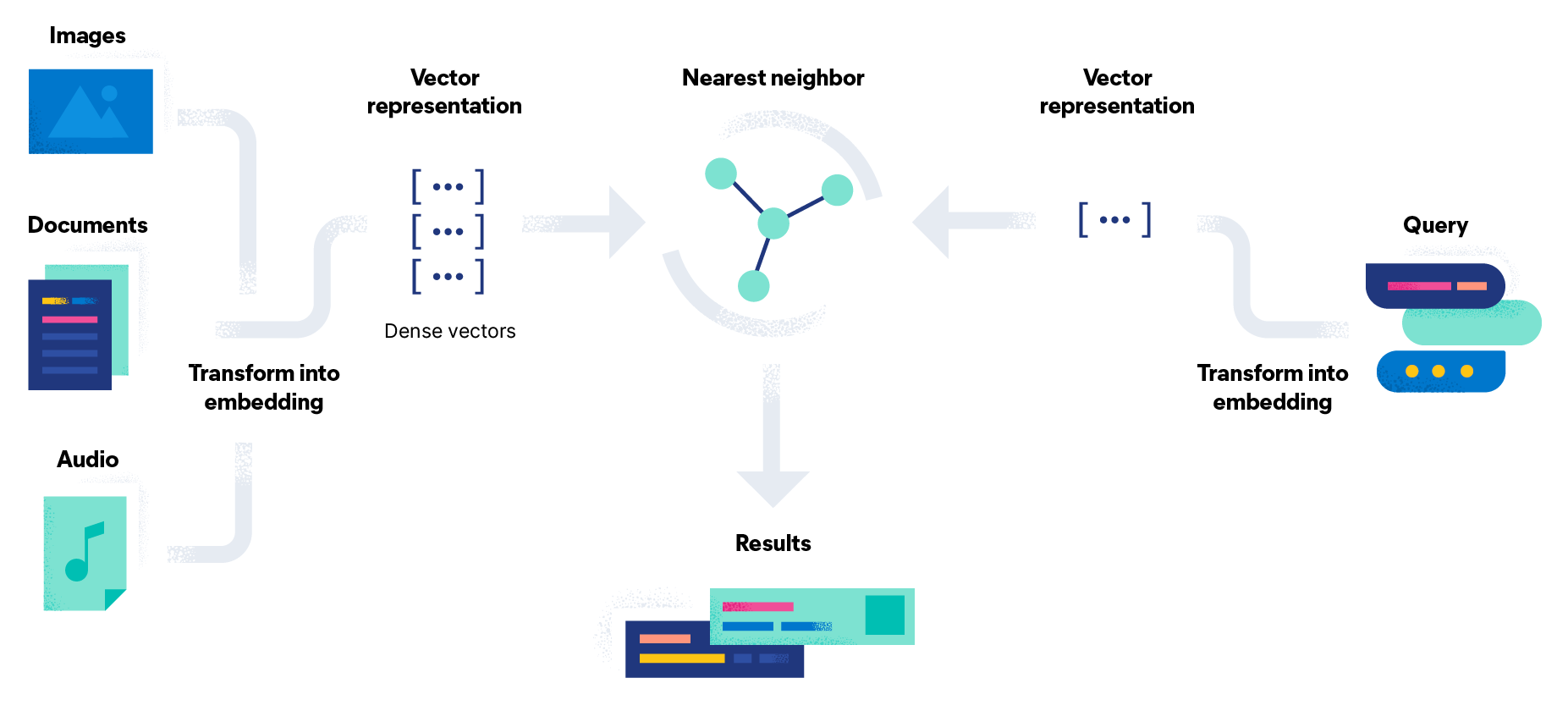
Implementing vector search and applying NLP models is not difficult. With the Elasticsearch Relevance Engine (ESRE), you get a toolkit to build AI-powered search applications that can work with Generative AI and Large Language Models (LLMs).
Using ESRE, you can build creative search applications, generate embeddings, store and search vectors, and perform semantic search through Elastic’s Learned Sparse Encoder. Learn more about using Elasticsearch as your vector database.
扫码关注不迷路!!!
郑州升龙商业广场B座25层
service@iqiqiqi.cn

联系电话:187-0363-0315
联系电话:199-3777-5101





